Joël de Bruijn
- 1 Post
- 52 Comments
Must admit, those fields are precisely the ones I use in my filenaming convention. Other DMS put that in their databases but alas that’s just trading one stack for another.
Other ones put it in XMP metadata of the pdf themselves. But I guess the work involved would be similar.
I don’t know.
- I don’t need formatting but it doesn’t get in the way either. So I am not bothered by it.
- Also pdf and especially PDF/A standard is widely used for archiving and compliance regulation concerning archival and preservation.
- If you want text the same tactic goes: just export in bulk to txt instead of pdf
My main point is: Why would you want a mail specific stack of hosting, storage, indexing and frontends? If it’s all plain text anyway so the regular storage solutions for files come a long way.
There is an entire industry (which has its own disadvantages) to get communication artefacts out of those systems and put it in document management systems or other forms of file based archival.
I had roughly the same goals ( archive search 2 decades of mail) but approached it completely different: I export every mail to PDF with a strict naming convention.
- Backend: No mailserver, just storage and backup for files.
- Search: based on filenames FSearch and Void tools Everything. I could use local indexing on pdf content.
- Frontend: a pdf viewer.

 3·9 days ago
3·9 days agoBecause the actual export, transform and loading of multiple banks and accounts data is cumbersome its holding me back.
So curious to read about GoCardless.
But is that also for consumer?
And is it this: https://gocardless.com/pricing/
 4·22 days ago
4·22 days agoNot for Photos specific but F2 seems to fit some of your use cases. https://github.com/ayoisaiah/f2
Even can use Exif fields as variables in the naming scheme. https://github.com/ayoisaiah/f2/wiki/Built-in-variables#3-exif-variables
If an historical timeline uses this labeling system it can’t omit the NT part though. Windows NiceTry came out in 1993 but also long after that MS had MS-DOS based editions (up until Windows Me iirc)
Isnt CAPSLOCK case for screaming? 😁
Also I’m very much cautious about them on anything browsing related. Discovered (after others also) they let their search-pages-in-a-shop get indexed.
Meaning I could go to Caterpillar, search for “Wabtec is better” and then this search url (with 0 products) would turn up in Google searches and that URL persisted. Text and all.
Basically one could spray-paint and tag sites with this graffiti. Shop admins didn’t even have means to remove it.
Problem ignored and stayed this way for months.
 5·3 months ago
5·3 months agoThanks for this write up, appreciated because sometimes (like on LinkedIn, I know don’t ask) it feels like everyone is an AI guru talking hype hype hype.
deleted by creator
Can confirm, tested it with Signal forum, also discourse. Fireshot stops at the end of the current loaded messages (20 of 94) and doesnt scroll further by itself.
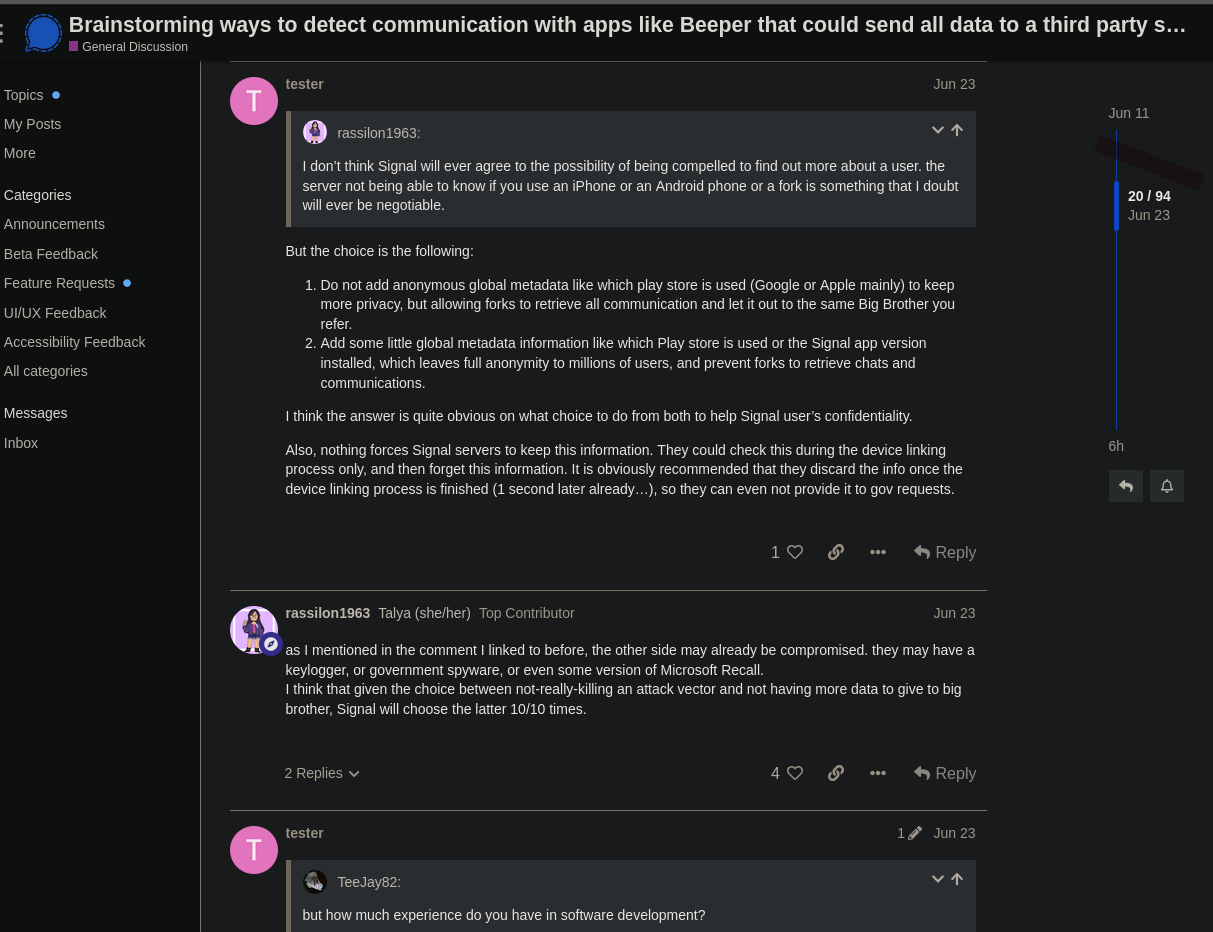
Not sure, search on “screenshot lazy load Fireshot” or “screenshot lazy load Linkwarden” does not turn up anything conclusive.
Do you have an example?
It’s also the use cases supported by Linkwarden:
Dont know if it’s illegitimate otherwise 😉
But my user story is like this:
I want to preserve and archive information I used because it’s a reflection of the things I did, learned and studied throughout life.
Then my use case are:
- Orientation about “events”: places to visit on daytrips or holidays (musea, nature, parks, campsites) and looking for practical information and background as well.
- Gather a “dossier”: info to help make a decision (buying expensive things, how to do home improvement etc)
- Building a personal knowledge database: interesting articles and blogs.
My current workflow:
- Browse
- Bookmark extensively
- Download pdf or other content (maps, routes, images) when provided.
- Open bookmarks.
- Fireshot every webpage to pdf and png
- Save everything with a consequent filename (YYYYMMDD - Source - Title)
I would like to automate the last 3 steps of my workflow.
This, but for a Fireshot like tool. Screenshot and pdf of webpages in their entirety by scrolling while shotting. In bulk, with CLI.
Restic Backup!
I have a floccus sync with NextCloud bookmarks but for long time archival and accessibility I use FireShot for pdf and png saving to local copy.
Your bookmark + pdf + image + html intrigued me but I is it possible to export in bulk these files for local archive and backup?
Got a work related variant, a 3 letter domain we really liked was registered by a person asking a couple of hundred bucks or so. Which really was a good deal and we were more then happy to pay.
Our IT department advised guiding the transfer themselves. Instead our marketing department went ahead anyway and just agreed to “you end your subscription and after that we register it” … instead of using transfer codes.
In the minutes between, a bulk claimer snatched it away.
{kind=link}
Its in the original post. To create a distraction less or more less environment to prepare for exams.