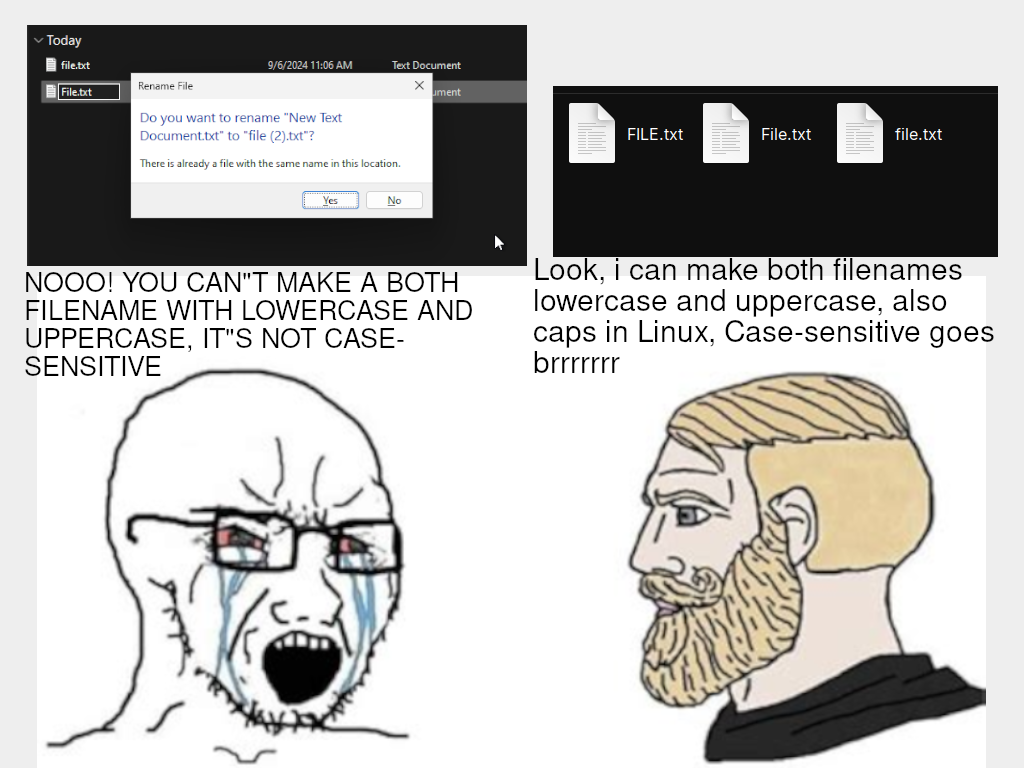
Case-sensitive is easier to implement; it’s just a string of bytes. Case-insensitive requires a lot of code to get right, since it has to interpret symbols that make sense to humans. So, something over wondered about:
That’s not hard for ASCII, but what about Unicode? Is the precomposed ç treated the same lexically and by the API as Latin capital letter c + combining cedilla? Does the OS normalize all of one form to the other? Is ß the same as SS? What about alternate glyphs, like half width or full width forms? Is it i18n-sensitive, so that, say, E and É are treated the same in French localization? Are Katakana and Hiragana characters equivalent?
I dunno, as a long-time Unix and Linux user, I haven’t tried these things, but it seems odd to me to build a set of character equivalences into the filesystem code, unless you’re going to do do all of them. (But then, they’re idiosyncratic and may conflict between languages, like how ö is its letter in the Swedish alphabet.)


{kind=link}
Case-sensitive is easier to implement; it’s just a string of bytes. Case-insensitive requires a lot of code to get right, since it has to interpret symbols that make sense to humans. So, something over wondered about:
That’s not hard for ASCII, but what about Unicode? Is the precomposed ç treated the same lexically and by the API as Latin capital letter c + combining cedilla? Does the OS normalize all of one form to the other? Is ß the same as SS? What about alternate glyphs, like half width or full width forms? Is it i18n-sensitive, so that, say, E and É are treated the same in French localization? Are Katakana and Hiragana characters equivalent?
I dunno, as a long-time Unix and Linux user, I haven’t tried these things, but it seems odd to me to build a set of character equivalences into the filesystem code, unless you’re going to do do all of them. (But then, they’re idiosyncratic and may conflict between languages, like how ö is its letter in the Swedish alphabet.)